Innovating at the Speed of Business: Announcing the Customer Achievement Awards AMER 2026 Finalists
We are honored to celebrate these remarkable achievements and the trust our customers place in
When most people think of A/B experimentation, they think of button colors, landing page layouts, or checkout flows. At Google, many fundamental infrastructure improvements also need the rigor of A/B experimentation. Optimizing a memory allocator or a kernel scheduler can unlock massive savings in compute resources and slash latency for millions of users. But experimenting with such critical changes is inherently risky; a buggy kernel update doesn’t just result in an unhappy user, it can take down large swaths of machines. To innovate safely and at scale, you must perform A/B experimentation on the infrastructure itself.
In this blog post, we summarize the key lessons from Google’s A/B experimentation methodology that we’ve refined over multiple years. This blog post is meant as a resource of best practices to follow and initiate a broader discussion around this topic (similar to our performance tips series). Specifically, we highlight four pillars of Google’s A/B experimentation infrastructure:
Application-level vs. machine-level experimentation
Maintaining a balanced setup
Ensuring binary hermeticity
Selecting the right performance metrics
In the following section, we explore why these aspects are critical and how we have handled these at Google.
Experiments targeting the core building blocks of your stack — such as the operating system, core libraries, compilers and the cluster management system — help unlock performance and efficiency gains that application experiments simply cannot achieve alone. These experiments provide a reliable and safe way to measure impact at a massive scale using a representative subset of the fleet. This helps inform which optimizations are worthwhile.
At Google, we see high value in optimizing the following specific components:
It’s easy to measure changes that bring large improvements, such as rewriting an entire memory allocator for a 2x efficiency gain. At Google scale, however, the reality is a lot of our infrastructure improvements are much smaller — typically sub-1% gains. But while an individual change may seem minor, a sustained sequence of small optimizations accumulates with time, leading to moonshot-like returns.
Achieving these sub-1% gains demands careful thinking about experimentation and measurement. To do so, we built a robust framework for reliably performing A/B experiments and measuring the impact of small changes.
To evaluate infrastructure changes, you could enable the change on a specific set of applications and observe metric shifts. However, this application-centric approach has several critical drawbacks:
Selection bias: Individual applications may not be suitable for evaluating specific changes. For instance, an application that allocates memory only during startup is a poor candidate for testing updates to a memory allocation library.
Lack of fleet representation: A small group of applications rarely reflects the behavior of the entire fleet, leading to inaccurate estimates of potential improvements.
Invisible system-wide benefits: Measuring isolated applications fails to capture concomitant effects. For instance, a change that improves hardware cache performance may benefit all applications running on a machine, not just the one being measured.
Technical constraints: Fundamental system changes, such as those made to the kernel or cluster scheduler, simply cannot be evaluated effectively through individual applications alone.
At Google, we overcome these hurdles by enabling changes on individual machines rather than specific applications. All workloads running on a chosen machine actuate the change, allowing us to measure the impact across the entire fleet. This approach captures concomitant effects for all co-located applications and enables the evaluation of system-specific changes that application-level tests would miss.
A typical experiment selects 1% of the fleet for both the experiment and control groups. The experiment is then gradually rolled out in waves following internal best practices. During the rollout, the framework starts collecting data for both groups, and continuously analyzes it to measure impact on performance and detect production regressions.
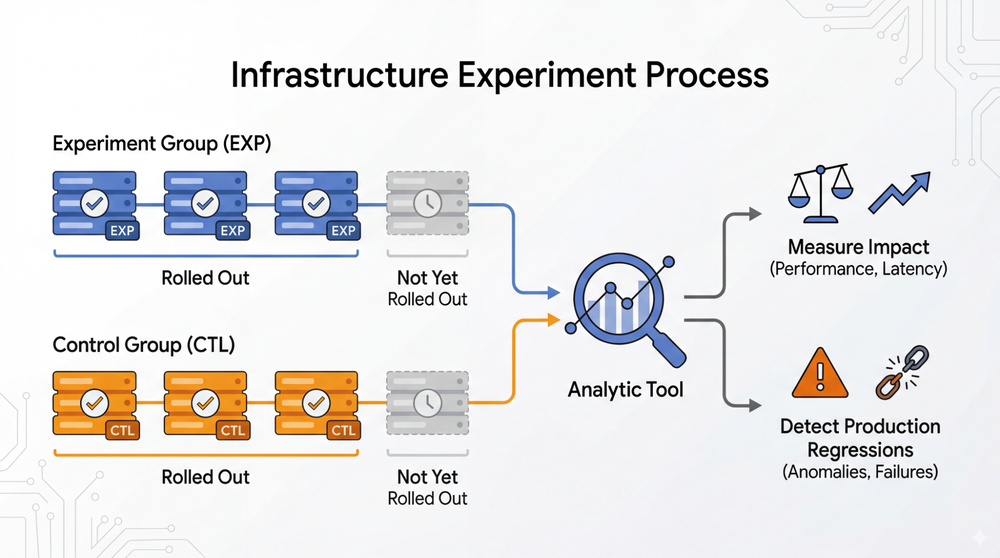
The validity of an infrastructure experiment hinges on how you select machines. You need to have balanced experiment and control groups, each targeting a representative subset of your machine fleet. Google’s fleet has several different machine types. The proportion of these machine types in the experiment and the control groups should closely match. When the machine types in the experiment and control groups did not closely match in just two clusters, we noticed a 0.2-0.3% data skew! For any sub-1% improvement, this is enough to invalidate the result.
The experiment and the control groups must also not be too large, or you risk the infrastructure’s overall reliability. Nor should they be too small, leading to statistically insignificant data. At Google, we concluded that a 1% subset of fleetwide machines hits the sweet spot.
Implementation-wise, we select 1% subsets of the fleet with a proportional representation of different generations of machines in each cluster. All these subsets are completely equivalent to one another and are rebalanced periodically using linear programming to limit the churn. When we deploy an experiment, two subsets are picked to serve as the experiment and control groups. Both groups roll out at the same pace so a balanced A/B analysis can be performed at any time.
For an experiment that modifies the behavior of a library, binaries must be recompiled with the experimental library change. Crucially, the experimental logic only activates when the binary is running on a machine in the experiment group.
Our experimentation framework includes a critical safety requirement designed to ensure that experiment rollbacks are simple and reliable. Any experiment that alters the behavior of individual binaries must follow a two-step rollout process:
First, the experiment is rolled out to all machines in the experiment and control groups.
Only then should the experimental library change be submitted, so that newly compiled binaries activate the experiment when they are deployed to the experiment machines.
This sequential approach makes it easy to tie any behavioral changes to binary releases. More importantly, it guarantees that rolling back to the previous version of the binary safely and immediately undoes the experiment.
What happens if you don’t follow this rule? When experiments cause production outages, it becomes extremely difficult to debug and mitigate them. To fully remove the experiment, you would need to roll back the machines and restart all the affected binaries. This delay could significantly slow down outage mitigation and could potentially cause even more damage.
To illustrate the risks, imagine running a core library optimization experiment that causes sporadic memory corruption. If the rollout steps above are switched, newly built binaries will contain the experimental change before the machine-level rollout even begins. Owners might incorrectly believe that these binaries are safe, since the experiment has not been activated yet. However, once the machine rollout starts, only the binaries built after the library change will show memory corruption, but others would not. This staggered failure makes it incredibly difficult to isolate the experiment as the root cause. If the owners attempt to roll back to the previous version of the binary, the corruption will persist, making incident response less effective. The sudden appearance of memory corruption and the search process needed for the right version of the binary complicates debugging.
Infrastructure experiments do not care about click-through rates, where short-term boosts may come at the cost of long term engagement. Instead, the focus is on the performance and the health of the applications and machines, as measured by:
Application productivity: At Google, we internally debated about the best metric to accurately measure performance. It is well known in academia that Instructions Per Cycle (IPC) is not a suitable metric for multiprocessor/multiprogrammed workloads. Instead, we opted for a robust, application-defined productivity metric that captures the amount of work done by the application. For example, a search web server reports the number of search queries completed per second as its productivity metric.
Machine-level performance: While application productivity is our gold standard, we also measure other metrics like IPC, cache misses, and memory bandwidth to corroborate performance improvements.
Reliability: We track multiple reliability metrics, including abnormal terminations and machine timeouts. Sure, a new kernel might be faster, but if it introduces new crashes, it is considered a failure and must be fixed.
We periodically collect these metrics from all applications on all machines in our fleet.
Running experiments and collecting data is only half of evaluating an optimization. A significant challenge lies in analyzing the collected data to understand how a change will truly impact the fleet before a full rollout. With thousands of jobs running in our data centers at any one moment, any single change has a varied effect on job performance. Further, it’s impossible to make an informed decision based on just a handful of jobs. To overcome this, we developed advanced statistical tools that meticulously match jobs running on the experiment group with comparable jobs on the control group. We then compare the metrics from these matched pairs and aggregate the results across all jobs to generate reliable metrics about the entire fleet. This comparison is done using data spanning several weeks to ensure that daily fluctuations do not skew our findings.
Furthermore, we regularly study data from A/A experiments to understand the variance caused by daily fluctuations. The data from these A/A experiments is used to establish a “noise floor.” Only changes that produce results significantly above this noise floor are considered robust and worthy of being rolled out.
As cloud infrastructure continues to expand, squeezing every bit of efficiency out of our resources is no longer just an advantage — it is necessary for sustainable cost management. This demand for efficiency requires a rigorous, data-driven approach to validate new optimizations, making robust, fleet-wide A/B experimentation infrastructure essential. However, this presents substantial challenges, encompassing configuration management, reliability, and statistical analysis — none of which are exclusive to our environment. By opening up about the infrastructure we have built at Google, we aim to spark a new wave of research and collaboration. We hope that sharing these hard-earned lessons will:
Offer researchers and practitioners a window into the intricate, high-stakes world of infrastructure-level experimentation
Provide a proven blueprint that others can adapt and improve upon within their own environments
Ignite bold new innovations that push the boundaries of what’s possible in systems performance.